 |
Proxy-GrundlagenDer Abruf externer WWW-Dokumente über das Internet kostet Zeit und Geld. Einiges davon läßt sich durch einen Proxy-Cache einsparen. "Proxy" bedeutet"Stellvertreter", denn der Proxy-Server ruft die Dokumente stellvertretendfür den Client im lokalen Netz ab. "Cache" bedeutet "Zwischenspeicher", dader Proxy abgerufene Dokumente auch für eine gewisse Zeit zwischenspeichert.Die Anbindung eines lokalen Netzes an das Internet stellt immer auch eingewisses Maß an Risiko dar. Das liegt daran, daß nicht nur Stationenim eigenen Netz Verbindungen nach außen aufbauen können, sondern derumgekehrte Weg ebenfalls möglich ist und sich neben erwünschtenBesuchern auch ungebetene Gäste im lokalen Netz tummelnkönnen. Ein Proxy kann hier einen Schutzschild bilden, wenn er der einzigeRechner mit Verbindung nach außen ist. Allen übrigen Rechnern bleibt allein derInhouse-Datenverkehr über das lokale Netz. Möchte ein Anwender ein Dokument voneinem WWW-Server im Internet abrufen, auf den er von seinem Rechneraus keinen Zugriff hat, wendet er sich (beziehungsweise seinWWW-Client) an den Proxy. Dieser läuft auf der Internet-berechtigtenMaschine im lokalen Netz und hat zwei Gesichter: Gegenüber demWWW-Client des Benutzers tritt er als WWW-Server auf und nimmt dieAnforderung entgegeben. Um das Dokument zu besorgen, das er selbstnicht besitzt, fungiert er gegenüber dem Originalserver alsWWW-Client, ruft das Dokument ab und leitet es dann an denanfordernden Client weiter.

Der Proxy beherrscht also beide Seiten der Kommunikation, die eines
Clients und die eines Servers. Zweckmäßigerweise spricht er außer HTTP
die übrigen im WWW unterstützten Protokolle, so daß der Durchgriff
etwa auf FTP etc. über den Proxy ebenfalls möglich ist. Das folgende
Bild zeigt einen über den Proxy laufenden FTP-Zugriff.

Eine per FTP vom Originalserver geholte Datei kapselt der Proxy in
eine HTTP-Response ein, läßt sie aber im Übrigen unverändert.
Verzeichnisse konvertiert er und stellt sie als Liste von Links dar.
Bevor der Proxy im Auftrag eines Client einen entfernten Zugriff
ausführt, kann er prüfen, ob der Client berechtigt ist, die
Proxy-Funktionalität zu nutzen. Fein abgestufte Mechanismen erlauben
dem Administrator, unterschiedlichen Benutzern unterschiedliche
Rechte zu geben.
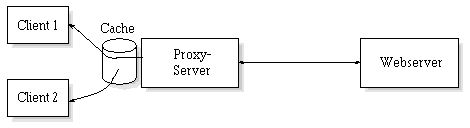
Noch interessanter wird es, wenn der Proxy-Server die von außen
geholten Daten nicht nur einfach an den Client weiterleitet, sondern
sie zusätzlich in einem Plattencache zwischenspeichert und sie dort
für künftige Zugriffe bereithält. Die Abbildung zeigt den Zugriff auf
ein entferntes Dokument durch Client 1. Der Proxy ruft die Seite ab,
stellt sie zu und legt sie gleichzeitig im Cache ab. Ruft nun ein
zweiter Client das gleiche Dokument ab, braucht der Proxy keine
Außenverbindung mehr aufzubauen, sondern kann die Anforderung
unmittelbar aus dem Cache heraus befriedigen.
Das Caching bietet mehrere Vorteile:
- Der Client erhält das angeforderte Dokument sehr schnell, da
lediglich eine lokale Verbindung zum Proxy nötig ist.
- Die Anfrage belastet die externe Anbindung nicht; die
Leitungsbandbreite bleibt für andere Dienste frei.
- Für den Transport des Dokuments vom Proxy zum Client fallen
keine Übertragungskosten an.
Die Erfahrungen zeigen, daß die Trefferquoten im Cache im Durchschnitt bei
rund 40 bis 50 Prozent liegen, der Proxy-Cache also fast jeden zweiten Zugriff
erspart. Besonders beliebte WWW-Seiten weisen noch erheblich höhere Trefferquoten
auf. Voraussetzung für optimales Caching ist ein genügend großer Cache-Bereich.
Ein kleinerer Cache läuft schneller über, so daß der Garbage collector häufiger
Dokumente entfernen muß. Das macht ein häufigeres Neuladen durch den Proxy
erforderlich und läßt die Cache-Trefferquote entsprechend sinken. Da der Proxy
einem WWW-Server gegenüber als ganz normaler Client auftritt, kann man zwei oder
mehr Proxies hintereinanderhängen und eine Kaskade aufbauen. Den handfesten
Vorteilen des Proxy-Caching stehen aber auch einige Nachteile gegenüber:
- Der Cache enthält möglicherweise eine veraltete Fassung des
Originaldokuments und liefert diese an den Client, anstatt die
aktuelle Version auf dem WWW-Server zu berücksichtigen.
- Wenn die Inhouse-Klienten nicht häufig auf dieselben Dokumente
zugreifen, also eine geringe Lokalität der Zugriffe vorliegt, ist
Caching nutzlos.
Das einzige wirklich wichtige Problem beim Proxy-Einsatz ist
das der nicht notwendigerweise aktuellen Dokumente. Verschiedene
Strategien versuchen, es zu meistern und dem Benutzer soweit irgend
möglich aktuelle Dokumente zu liefern. Ziel dieser Strategien ist es,
die Dokumente im Cache so häufig wie nötig zu aktualisieren, aber
gleichzeitig so wenig wie möglich externe Zugriffe
durchzuführen. Ausnutzen lassen sich dazu zwei HTTP-Features:
Last-Modified und Expires. Das Protokoll sieht in der Antwort des
Servers Informationen darüber vor, wann das Dokument zuletzt geändert
wurde (Header Last-Modified) und ab wann der Client (hier: der Proxy)
ein Dokument als veraltet betrachten soll (Header Expires). Die zweite
Information für sich genommen würde schon zur Problemlösung reichen,
weil man dank dieses Headers genau weiß, wann das Dokument
veraltet. Aber leider sind sowohl Last-Modified als auch Expires
lediglich optionale Header. In der Praxis kommt der Expires-Header
selten vor. Die meisten Dokumente besitzen kein vorher definiertes
Verfallsdatum; sie sind einfach solange gültig, bis der Autor eine
neue Version erstellt.
Die meisten Server liefern bei statischen Dokumenten meist den
Last-Modified-Header mit. Diesen Zeitstempel herauszufinden ist
nicht schwer, da jede Datei diese Information mit sich trägt.
Mit Hilfe von Last-Modified implementiert der Proxy ein heuristisches
Verfahren. Die zugrundeliegende Überlegung: Liegt die letzte Änderung
eines Dokuments schon Monate zurück, ist die Wahrscheinlichkeit recht
gering, daß ausgerechnet in den nächsten paar Stunden eine Modifikation
erfolgt. Sofern das Dokument allerdings erst vor kurzem aktualisiert
wurde, ist die nächste Veränderung bestimmt nicht weit.
Eine weitere Optimierung sorgt dafür, daß der Server das Dokument
nur dann schickt, wenn er eine neuere Version besitzt als der
Cache. Dazu übermittelt der Proxy dem Server den
Last-Modified-Zeitstempel der Dokumentversion, die er im Cache
hält, so daß der Server entscheiden kann, ob er selbst über eine
aktuellere Fassung verfügt, z. B.:
GET /index.html HTTP/1.0
If-Modified-Since: Monday, 10-Jun-02 13:26:12 GMT
Ist die alte Version noch immer die aktuelle, teilt der Server dem
Proxy dies in einer kurzen, nur aus HTTP-Headern bestehenden Nachricht
mit.
Der HTTP-Header
Pragma: no-cache
teilt dem Proxy den Wunsch des Clients mit, den Originalserver zu
befragen. Die Optimierung mit If-Modified-Since kommt bei HTTP-Servern
auch hier zum Tragen.
Sicherheitsaspekte
Der Proxy-Betreiber will seinen Service in der Regel nur einer bestimmten
Benutzergruppe zur Verfügung stellen. Der Anwender will durch den Proxy-Betrieb
auch keine Schwierigkeiten haben. Und schließlich möchte der Anbieter von
solchen Dokumenten, die eine Autorisierung verlangen, nicht, daß seine
Seiten in irgendeinem Proxy-Cache herumliegen und wohlmöglich von
jedem beliebigen Interessenten unkontrolliert gelesen werden können.
Stellt der Benutzer seinen Client auf Proxy-Betrieb um, kann
er bei geschützten Dokumenten durchaus Probleme bekommen. Es ist ja
jetzt der Proxy, von dem der Server die HTTP-Anforderung empfängt, und
nicht mehr der Client. Und wenn ein Dokument nur an Rechner mit
bestimmten IP- oder Domain-Adressen ausgeliefert wird, lehnt der
Server die Anforderung ab, sofern der Proxy-Server in dieser Liste
nicht registriert ist. Andererseits können sämtliche Kunden des
Proxies das Dokument ebenfalls erhalten, wenn der Proxy-Server
zugriffsberechtigt ist.
Bei Dokumenten, die ohne Rücksicht auf die Rechneradresse durch "Basic
Authentication" gesichert sind, für die sich der Anwender also mittels
Benutzerkennung und Paßwort ausweisen muß, bereiten keine Probleme. Die Antwort
vom Originalserver enthält bei unautorisiertem Zugriff den HTTP-Header
WWW-Authenticate: Basic realm="name"
Der Client versieht Zugriffe auf derart geschützte Dokumente mit dem Header
Authorization: Basic user:password
Der Proxy-Server reicht diese Header in beide Richtungen unverändert durch
und stellt daher kein Hindernis dar. Derart geschützte Dokumente nimmt der
Proxy nicht in den Cache auf, um unberechtigten Abrufen vorzubeugen.
Der Zugriff über den Proxy an Stelle des direkten Zugriffs tritt
übrigens auch an einem anderen Punkt als Problem zutage, nämlich wenn
ein CGI-Script auf dem Originalserver von den Environment-Variablen
REMOTE_HOST oder REMOTE_ADDR Gebrauch macht. Beim Proxy-Zugriff
enthalten diese Variablen die Daten das Proxies und nicht die des
wirklichen Clients.
Port-Weiterleitung mit rinetd
rinetd ist ein einfacher TCP-Proxy, der auf Verbindungen zu IP-Ports lauscht
und die Datenpakete auf andere Rechner und Ports umleitet. Diese Zielrechner sind für
gewöhnlich Server innerhalb eines privaten (Masqueraded) Netzwerks, die zwar dem
Gateway, nicht aber dem Rest der Welt bekannt sind. So können beispielsweise die
80er Ports verschiedener virtueller Netzwerkkarten auf bestimmte Ziel-Server umgeleitet
werden. In der aktuellen Version von inetd werden nur TCP-Verbindungen berücksichtigt.
Auch Verbindungen, die mehrere Ports verwenden (z. B. FTP), werden nicht unterstützt.
Die Weiterleitungs- und Zugangsregeln werden in /etc/rinetd.conf festgelegt.
- Weiterleitungsregeln
Diese Regeln bestimmen Verbindungen von einem Adress/Port-Paar zu einem anderen.
Das Format ist
bindaddress bindport connectaddress connectport
Um zum Beispiel den Webserver mit der Adresse 10.1.1.1 auf jenen mit der Adresse
10.1.1.2 umzuleiten, genügt die Regel:
10.1.1.1 80 10.1.1.2 80
Statt der IP-Adresse sind auch Domainnamen erlaubt. Sollen mehrere Adressen auf ein Ziel
geleitet werden, muß nicht für jeden Rechner eine eigene Weiterleitungsregel geschrieben
werden. So wird durch
0.0.0.0 80 10.1.1.2 80
alles was von außen an Port 80 geht auf 10.1.1.2 umgeleitet. So kann man auch temporär
schnell mal Dienste umleiten.
- Zugangregeln
Weitere Regeln dienen zur Zugangskontrolle. Wenn die Adresse einer neuen Verbindung mit
einer "Deny"-Regel übereinstimmt oder nicht in einer der "Allow"-Regeln zu finden ist,
wird die Verbindung verweigert. Sollen die Zugangsregeln global gelten, müssen sie
am Anfang der Konfigurationsdatei stehen. Stehen Sie hinter einer bestimmten Weiterleitungsregel,
gelten sie nur für diese spezielle Weiterleitung. Zum Beispiel wird mit:
allow 10.1.1.*
10.1.1.1 80 10.1.1.2 80
so werden nur noch die Anfragen aus dem Netz 10.1.1.0 weitergeleitet. Im folgenden
Beispiel gilt diese Einschränkung nur für die erste Regel, nicht für die weiteren:
10.1.1.1 80 10.1.1.2 80
allow 10.1.1.*
10.1.1.3 80 10.1.1.2 80
10.1.1.4 80 10.1.1.2 80
In diesen Regeln sind nur IP-Nummern und keine Hostnamen erlaubt.
Bei den IP-Angaben können Muster verwendet werden, wobei "?" für eine beliebige Ziffer
steht und "*" für eine beliebige Ziffernfolge (auch Null).
Auf Wunsch erzeugt rinetd ein Logfile. Dazu muß die Zeile
logfile /var/log/rinetd.log
den Pfad zum Logfile angeben. Voreinstellung ist ein tab-delimited Format, welches
folgende Informationen enthält:
- Date and time
- Client address
- Listening host
- Listening port
- Forwarded-to host
- Forwarded-to port
- Bytes received from client
- Bytes sent to client
- Result message
Durch die zusätzliche Zeile logcommon wird das Common Logfile Format (CLF)
verwendet, das auch Apache und Squid erzeugen und das mit vielen Analysetools
ausgewertet werden kann.
|
|
|
