 |
HochverfügbarkeitBereits ein unvorhergesehener Ausfall für von wenigen Minuten kannden Betreiber eines Dienstes in große finanzielle Schwierigkeitenbringen. Hinzu kommt ein nicht näher zu beziffernder Imageverlust. Ein Unternehmen im Zeitalter des e-Business kann es sich nichtleisten, für einen spürbaren Zeitraum vom Netz zu sein.Jeder Verantwortliche muß sich nun überlegen, ob dieVorteile eines hochverfügbaren Systems nicht bei weitem gegenüber seinen Nachteilen (Kosten) überwiegen. Was bedeutet "hochverfügbar" eigentlich?Die Größe, von der in diesem Zusammenhang am meisten dieRede ist, ist die der prozentualen Verfügbarkeit eines Dienstes(Wartungsfenster für die betroffenen Server sind hierbeiausgenommen). Die folgende Tabelle vermittelt ein Gefühl fürdie tatsächlichen Ausfallzeiten, die hinter den prozentualenVerfügbarkeitsangaben stecken.
| Verfügbarkeit (%) | Ausfallzeit | | 99% | 3,6 Tage | | 99,9% | 8,76 Stunden | | 99,99% | 52 Minuten |
| 99,999% | 5 Minuten |
| 99,9999% | 30 Sekunden |
| 99,99999% | 3 Sekunden |
Wie erreicht man Hochverfügbarkeit?
- Fehlervermeidung, d.h. geeignete Maßnahmen beim Entwurf, bei
der Spezifikation und bei der Implementierung des Systems zur Vermeidung
von Fehlern. Das ist i.d.R. unmöglich, da Fehler in der Hardware
oder in der Software meist nicht vohersehbar sind
- Fehlertoleranz, d.h. Sicherung der Funktionalität des Systems
beim Auftreten von Problemen und Fehlern im laufenden Betrieb
Damit werden notwendig:
- Fehlerbehebungstechniken, z.B. Festlegen von Zeitpunkten (Checkpoints),
an denen im Fehlerfall ein System wieder neu aufsetzen kann, sodaß
eine Operation nicht erneut von Anfang an laufen muß
- Fehlerkompensierungstechniken, d.h. Erkennen von Fehlern und ihre
Kompensation durch:
- Fehlerkorrektur, z.B. ECC bei RAM-Speicher
- Fehlermaskierung, z.B. durch Vergleich mit Duplikat etwa bei Plattenspiegelung,
d.h. Anlegen einer Kopie, Abgleich von Original und Kopie, Erkennen eines
Fehlers im Original und Lieferung eines korrekten Results von der Kopie
Zum einen müssen SPOFs (Single Points of Failure) korrekt
indentifiziert und anschließend eliminiert werden. SPOFs sind
diejenigen Komponenten, deren Ausfall den Komplettausfall des gesamten
Dienstes bedeuten würde. Zum anderen muß die
Dienstverfügbarkeit bei Ausfall eines einzelnen Systems
sichergestellt werden. Ob der konkrete Rechner in diesem Fall
erreichbar ist oder nicht, spielt keine Rolle. Wichtig ist in diesem
Fall, daß ein anderer Rechner nahtlos dort weiterarbeiten kann,
wo sein "Kollege" aufgeben mußte.
Das Zauberwort im Falle der SPOFs heißt Redundanz, einfach
gesagt: Jede Komponente, ob Netzteil, Festplatte oder Netzwerkkarte
sollte mit einem "Stellvertreter" abgesichert sein, der die
Funktion der ausgefallenen Komponente wenn nötig übernimmt.
Damit ist der Redundanzen aber noch nicht genug, auch der Server als
Ganzes sollte abgesichert sein. Konsequent im SPOF-Schema
gedacht, stellt der Raum, das Gebäude oder sogar die Gegend, in
der der oder die Server stehen, wieder einen Single Point of Failure
dar. Um Ausfälle des gesamten Dienstes durch Gebäudebrand
etc. auszuschließen, sollte der Backupserver räumlich
getrennt vom Hauptserver betrieben werden.
Methoden der Fehlertoleranz
Murphys Gesetze kennen die meisten. Werden diese auf den Betrieb von lokalen Netzen
übertragen, ist es denkbar, daß sie lauten: "Falls eine Komponente
ausfallen kann, so wird sie früher oder später ausfallen. Hat eine
Komponente eine garantierte Funktionsfähigkeit für N Tage, wird sie nach
N+1 Tagen ausfallen. Sicherheitsinitiativen schieben die Katastrophe nur hinaus.
Die Fehlertoleranz nimmt zum Ausgangspunkt, daß Komponenten früher oder
später unweigerlich ausfallen, aber der Ausfall von Komponenten nicht zu
größeren Betriebsstörungen führen darf. Wenn man sich bewußt
ist, daß Betriebsunterbrechungen auftreten können, ist die Anschaffung von
fehlertoleranten Komponenten nur der erste Schritt. Übergeordnet betrachtet sind
es nicht nur die Komponenten, sondern ein zusammenhängendes System, dessen
fortgesetzter Betrieb vom schwächsten Glied abhängig ist. Ein fortschrittliches
Backup-System nutzt nur dann etwas, wenn es regelmäßig benutzt wird, an eine
stabile Stromversorgung angeschlossen ist, und die Sicherheitskopien in sicheren
physischen Umgebungen plaziert werden.
- Unterbrechungsfreie Stromversorgung (USV, UPS)
Überwachung der Stromversorgung des Systems, Ausgleich von Spannungsschwankungen
durch Pufferbatterien und Übernahme der Stromversorgung bei Stromausfall zum
sicheren Herunterfahren des Systems.
- Hot-Fix-Mechanismus
Auf der Festplatte wird ein kleiner Bereich als Hot-Fix-Bereich reserviert. Wird beim
Schreiben ein defekter Sektor festgestellt, wird dieser Sektor in der Bad-Sector-Table
als fehlerhaft eingetragen. Als Ersatz wird ein Sektor aus dem Hot-Fix-Bereich genommen,
in den die Daten dann geschrieben werden. Das Verfahren kann nicht vor späterer
Zerstörung korrekter Sektoren schützen.
- Read-After-Write-Verification (Kontrollesen)
Ein Datenblock wird aus dem Cache auf die Platte geschrieben und anschließend
sofort wieder eingelesen. Die Daten aus dem Cache werden also mit den gerade gelesenen
Block verglichen und bei Differenz eine Korrekturmaßnahme (z.B. Hot-Fix)
angeworfen.
- Redundante Dateisysteme
Die Bereiche der Platten mit den Informationen über die Organisation der
Datenblocks und die Zuordnung von Datenblöcken zu Dateien und Verzeichnissen
(Superblocks, File Allocation Table usw.) werden mindestens doppelt gehalten.
- Festplattenstriping (ohne Parität; RAID Level 0)
Es erfolgt eine Verteilung der Daten auf mehrere Festplatten (eigene Subsysteme,
RAID-System, Disk Arrays). Zum Beispiel werden bei 4 Platten von jedem Byte die
Bits 1,2 auf Disk A, 3,4 auf Disk B, 5, 6 auf Disk C und 7,8 auf Disk D geschrieben.
Dies ergibt jedoch keine Erhöhung der Datensicherheit, da keine Redundanz
vorhanden ist. Bei Ausfall einer Platte sind alle betroffenen Daten verloren
- Redundantes Festplattenstriping (ohne Parität)
Dies ergibt eine Erhögung der Sicherheit, da Daten redundant auf mehrere Platten
gespeichert werden. Zum Beispiel werden bei 4 Platten von jedem Byte die Bits
1,2,3,4 auf Disk A, 5,6,7,8 auf Disk B, 3,4,5,6 auf Disk C und 7,8,1,2 auf Disk D
geschrieben. Bei Ausfall einer Platte erfolgt Zugriff auf die redundanten Informationen.
- Plattenspiegelung (Disk Mirroring, RAID Level 1)
Einsatz von zwei identischen Platten, wobei die Daten der ersten Platte immer auch
auf die zweite Platte gespiegelt werden. Bei Ausfall der ersten Platte kann auf
die identischen Daten der zweiten Platte zugegriffen werden. Es gibt jedoch einen
Performanceverlust beim Schreiben, da auf zwei Platten geschrieben werden muß.
- Kanalspiegelung (Disk Duplexing)
Es handelt sich um den Einsatz von zwei identischen Platten an zwei Kontrollern.
Damit ist auch ein Schutz bei Ausfall eines Plattenkontrollers gegeben. Es gibt kaum
Einbußen beim Schreiben und eine deutliche Verbesserung beim Lesen, da ein
paralleler Zugriff auf beide Platten möglich ist.
- Disk-Striping mit Parität auf eigener Platte (RAID Level 4)
Die Daten werden auf mehrere Platten verteilt und die Paritätsinformationen
auf eigene Platte geschrieben. Bei Ausfall einer Datenplatte sind Daten durch
Paritätsinformationen rekonstruierbar. Ein Verlust von Daten tritt erst
bei Ausfall einer Datenplatte und der Paritätsplatte ein. Der Schreibvorgang
wird verlangsamt, da Berechnung und Schreiben der Paritätsinformationen notwendig
ist.
- Disk-Striping mit Parität auf mehreren Platten (RAID Level 6)
Die Daten werden auf mehrere Platten verteilt; die Paritätsinformationen werden
ebenfalls auf mehrere Platten verteilt. Es ergibt sich eine Verbesserung des
Schreibvorgangs durch Verteilung der Paritätsinformationen.
- Transaction Tracking System (TTS)
Ein TTS dient dem Schutz vor Inkonsistenzen insbesondere bei Datenbanken durch
unvollständige Transaktionen. Die Originaldateien werden unmittelbar vor
dem Öffnen in einen für das TTS reservierten Bereich kopiert. Bbei
korrekten Abschluß der Transaktion kann Kopie gelöscht werden.
Bei einem Fehler kann mit der Kopie und ihren konsistenten Daten weitergearbeitet
werden. Man unterscheidet:
- implizites TTS: Festlegung durch Datenbanksystem z.B. mit entsprechenden
Dateiattributen (problematisch bei großen DB-Dateien, da ganze DB-Datei
kopiert wird).
- explizites TTS: Festlegung durch Programm bzw. Programmierer, welche
Dateien oder Teile von Dateien von Transaktion betroffen sind (schneller
und günstiger, da nicht die ganze DB-Datei kopiert werden braucht).
- Server-Duplexing (RAID Level 10)
Die Vorgänge innerhalb eines 2-Node-Clusters beim Ausfall eines
Knotens und die verschiedenen Arten des Standby-Systems, das bei Bedarf
übernimmt, werden in Folgenden skizziert.
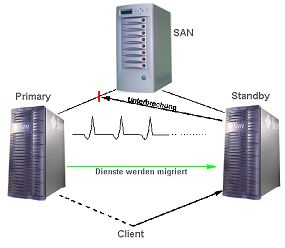
Die beiden Server (Primary und Backup) stehen beide ü,ber ein SAN
(Storage Area Network) in Verbindung. Je nach Betriebsart greift nur
der jeweils aktive Knoten hierauf auch zu. Untereinander kommunizieren
beide, indem sie sich regelmäßig "Lebenszeichen"(Heartbeat)
senden. Sterben die Lebenszeichen des Hauptsystems ab, wird das Standby-System
aktiviert, übernimmt die Dienste des ausgefallenen Partners und unterbricht
dessen Verbindung zum SAN.
Fällt in einem 2-Node-Cluster die interne Kommunikation aus, glauben beide
Knoten, der jeweils andere wäre nicht mehr aktiv. Sie versuchen dann beide
gleichzeitig, für den jeweils anderen einzuspringen und sich vom SAN
abzuschneiden. Eine solche Situation wird vermieden, indem ein bestimmtes
Übernahme-Verhalten beim Einrichten des Systems vordefiniert wird.
Hat die Dienstverfügbarkeit des Clusters höchste
Priorität, ist der Einsatz eines Load Balancers zu
überlegen. Ein Load Balancer nimmt eine Anfrage von einem Client
(z.B. eine http-Verbindung, um eine Website herunterzuladen) an und
verteilt diese dann an einen verfügbaren Server. Dies bietet sich
insbesondere bei WWW- und Mail-Diensten, Proxy-Servern, Firewalls und
ähnlichem an.
Standby-Strategien
Die bisherigen Betrachtungen bezogen sich auf die Eingenschaften einzelner
Rechner- und Betriebssysteme. Sie helfen, einen akuten Defekt nach
außen hin zu verbergen. Deshalb dürfen die Reparaturzeiten
aber nicht länger werden. Es muß also auch redundante Hardware
bereitgestellt werden. Dafür gibt es drei grundlegende Methoden:
- Cold-Standby
Die Ersatzhardware steht "kalt" bereit. Die Übernahme
muß manuell erfolgen, so daß der Ausfall dementsprechend
auch deutlich spürbar ist.
- Warm-Standby
Ein Backupsystem läuft im Hintergrund mit, so daß die
Übernahme automatisch erfolgen kann. In regelmäßigen
Zeitabständen werden die Daten auf beiden Systemen
synchronisiert. Der Ausfall ist nur kurz für den Benutzer
spürbar, allerdings kann die aktuelle Transaktion
möglicherweise verloren gehen, da die Daten vor dem Ausfall
nicht mehr synchronisiert werden konnten.
- Hot-Standby
Beide Systeme laufen ständig parallel, die Daten auf beiden
Systemen sind hundertprozentig synchron. Der Benutzer spürt
nichts von eventuellen Ausfällen. Meist ist diese Stufe nicht
ohne eine entsprechende Modifikation des Clients zu erreichen. Um
beide Systeme 100% synchron zu betreiben, müssen auch die
Verbindungen zum Client 100% gespiegelt werden. Dafür braucht
man "normalerweise" Clients, die Verbindungen zu zwei oder
mehr Servern gleichzeitig halten und mit allen reden. Das kann
beispielsweise ein normaler Webbrowser nicht.
Nimmt man die USV hinzu, lassen sich die Standby-Stufen folgendermaßen einteilen:
| Stufe 1: |
USV-Sicherung der Stromversorgung
Sicherheitskopie (Band)
|
| Stufe 2: |
USV-Sicherung der Stromversorgung
Sicherheitskopie (Band)
Plattenspiegelung (RAID 1)
|
| Stufe 3: |
USV-Sicherung der Stromversorgung
Sicherheitskopie (Band)
Plattenduplizierung (Plattenspiegelung + doppelter Controller)
|
| Stufe 4: |
USV-Sicherung der Stromversorgung
Sicherheitskopie (Band)
Plattenduplizierung (Plattenspiegelung + doppelter Controller)
Ersatzserver (cold Stand-by)
|
| Stufe 5: |
USV-Sicherung der Stromversorgung
Sicherheitskopie (Band)
Plattenduplizierung (Plattenspiegelung + doppelter Controller)
Serverduplizierung (hot Stand-by)
|
RAID - fehlertolerante Festplatten
RAID (Redundant Array of Inexpensive Disks) ist eine Alternative zu traditionellen
Speichersystemen, die aus einzelnen großen Festplatten bestehen. RAID-Systeme
bestehen aus einer Koppelung mehrerer kleiner und identischer Festplatten.
Aus dem Blickwinkel des Anwenders betrachtet, tritt ein RAID-Laufwerk wie ein
Laufwerk auf, im Gegensatz zu mehreren separaten Laufwerken, wie man es von Rechnern mit
mehreren Festplatten oder Partitions kennt. Entscheidender ist der Unterschied, daß
der Inhalt einer gegebenen Datei niemals auf einer einzelnen Festplatte plaziert ist,
sondern auf mehrere Platten im RAID-System verteilt ist, was zusammen mit der Datenredundanz
und Prüfinformationen bewirkt, daß keine Daten verloren werden, auch wenn eine
der Festplatten fehlerhaft ist. Sind die Platten des RAID-Laufwerks während des
Betriebs auswechselbar (hot-swapable), wird der Zugang zu Daten im RAID-Laufwerk
aufrechterhalten, auch wenn eine Festplatte im RAID-Laufwerk ausfällt und ausgewechselt
werden muß. Die RAID-Technik hat auch Konsequenzen für die Leistung des
Plattensystems. Manche RAID-Laufwerke können Daten parallel lesen und schreiben,
d. h. Information zwischen den Laufwerken auf Bit-, Byte- oder Blockebene über
data striping aufteilen. Fortschrittliche Festplattencontroller können außerdem
mehrere Positionieranforderungen für den Schreib-Lesekopf gleichzeitig handhaben,
eine Suchtechnik, die die Zugriffszeit wesentlich verkürzt. Während eines der
Laufwerke positioniert, wird von den übrigen gelesen.
Es gibt bei RAID verschiedene Kategorien, die unterschiedliche Stärken und
Schwächen haben. Die optimale RAID-Installation hängt vom Aufbau des Netzes
und den Sicherheitsanforderungen ab.
Der RAID-Level 0 bezeichnet ein Verfahren, bei dem die Daten auf mehrere
"Stripes" verteilt werden. Dies kann sowohl auf einem einzigen Datenträger
als auch auf verteilten Platten geschehen. Letzteres beschleunigt die
Zugriffszeiten und steigert die Kapazität des Speichers erheblich. Allerdings
wird bei RAID 0 keinerlei Redundanz vorgesehen. Im Falle des Defektes
eines einzigen Datenträgers des RAID-0-Systems ist mit einem totalen Datenverlust
zu rechnen. Der Vorzug dieses Verfahrens liegt also in der Geschwindigkeit
durch den parallelen Plattenzugriff und in der erhöhten Kapazität durch die Summe
aller Einzelplatten, nicht jedoch in der Sicherheit.
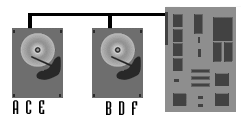
Im Beispiel unten wird das Datum "ABCDEF" in einzelne Blöcke zerlegt,
die abwechselnd auf beiden Festplatten geschrieben werden. Die Verwaltung des
Striping-Verbandes geschieht vollständig auf Controllerebene, belastet also nicht
die CPU. RAID-0 bei allen vom Computer unterstützten Betriebsystemen sofort
leistungssteigernd eingesetzt werden und der Host wird durch die Organisation des
Striping-Verbandes nicht zusätzlich belastet. Die Verbundenen Laufwerke bilden
ein einziges logisches Laufwerk.
Beim RAID-Level 1 werden zwei Laufwerke parallel betrieben und die Daten
vollständig gespiegelt. Ein Gewinn an Geschwindigkeit wird mit diesem Verfahren
nicht erzielt, und die Kapazität des RAID-1-Systems entspricht lediglich
der einer einzigen Platte. Allerdings ist die Ausfallsicherheit der Daten maximal,
denn selbst bei einem Totalausfall eines Laufwerkes stehen die Daten nach wie vor
vollständig auf der zweiten Platte zur Verfügung. Für Wartungszwecke
kann einer der beiden Datenträger gegebenenfalls auch während des laufenden
Betriebes entnommen werden ("hot swap").
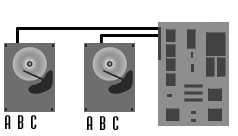
Das heißt auch, daß der Anwender ohne Unterbrechung mit dem
Mirroring/Duplexing-Laufwerk weiterarbeiten kann. Sind die Festplatten an einen
Kanal angeschlossen, so nennt man dies "Mirroring". Werden die Laufwerke
an zwei verschiedenen SCSI Kanälen betrieben, so ist dies "Duplexing".
Hierbei erhält man auch eine Leistungssteigerung. Das Schreiben der Daten kann
zeitgleich erfolgen und beim Lesen der Daten kommt das SCSI-Laufwerk zum Zug, das
als erstes und damit am schnellsten die Daten liefern kann.
Der RAID-Level 2 brachte einen großen Fortschritt, denn dieses Verfahren
ist ein wirtschaftlicher Kompromiß aus den beiden ersten Leveln. Die Daten werden
auf die einzelnen Laufwerke des Arrays aufgeteilt, wodurch die Geschwindigkeit und die
Performance des gesamten Speichers optimiert wird. Darüber hinaus wird ein Error
Correction Code (ECC) generiert und ebenfalls gespeichert. Das Verfahren ist heute
jedoch kaum noch anzutreffen, weil die Festplatten inzwischen Sicherungsfunktionen
implementiert haben.
Bei den RAID-Leveln 3 und 4 werden zwei bis vier Laufwerke verwendet, auf
denen die Nutzdaten gleichmäßig verteilt abgelegt werden. Darüber
hinaus ist ein weiteres Laufwerk vorgesehen, auf dem eine Paritätsinformation
gespeichert wird. Die Paritätsinformation der RAID-Level 3 und 4 werden auf
einem eigenen Datenträger gespeichert. Der Unterschied beider Level liegt in
der Größe der Nutzdatenblöcke. Während beim RAID-Level 3 die
Nutzdaten Byteweise gespeichert werden, werden im Level 4 größere
Blöcke verwendet.
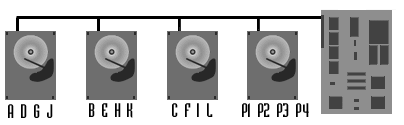
Bei jedem schreibenden Zugriff muß immer die Sicherheitsinformation für
die entsprechende Zeile berechnet und auf das Parity Laufwerk geschrieben werden.
Hierdurch wird das Parity-Laufwerk zum Flaschenhals des gesamten RAID Verbandes.
Die Datenlaufwerke sind bei schreibenden Zugriffen kleiner Datenblöcke entsprechend
schwach ausgelastet, wo hingegen auf das Parity-Laufwerk stets zugegriffen wird.
Der RAID-Level 5 gehört zu den am weitesten verbreiteten Varianten eines
RAID-Konzeptes. In diesem Fall werden die Vorzüge des RAID-Levels 4 weiterhin genutzt
und die Daten neben zusätzlichen Paritätsinformationen gespeichert. Der Vorteil
gegenüber dem Level 4 besteht jedoch in einem Verzicht auf einen eigenen
Datenträger für die Ablage der Checksummen.
Diese werden mit den eigentlichen Nutzdaten auf alle Platten des Arrays verteilt. Dabei
wird jeweils ein Block auf eine Platte und der nächste Datenblock auf das folgende
Laufwerk geschrieben. Aus der Sicht der Platten stellen sich die Paritätsdaten
wie eine Erweiterung der Nutzdaten dar. Kleine RAID-Systeme können so platzsparend
gebaut werden.
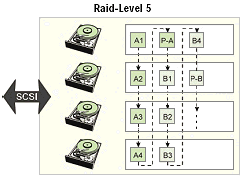
Der sehr weit verbreitete RAID-Level 5 zeichnet sich durch hohe
Fehlertoleranz und gute Performance aus. Allerdings wird die Integration der Paritätsdaten
in die Nutzdatenstruktur wieder mit einem gewissen Verzicht Sicherheit erkauft. Ist
beispielsweise in einem RAID-4-System eine Platte gestört, so können die Daten anhand
der Paritätsinformationen, die sich auf einer eigenen Platte befinden, wieder sauber
regeneriert werden. Fällt die Paritätsplatte selbst aus, dann ist dies unkritisch,
weil die originalen Informationen nach wie vor in unveränderter Form erhalten sind.
Anders beim RAID-Level 5. Hier kann es (wenn auch sehr unwahrscheinlich) vorkommen,
daß einzelne Daten im Störungsfall nicht mehr regenerierbar sind.
Auch bei diesem Level werden die Daten (ABCDEF...) über mehrere Platten verteilt und
pro Zeile (A,B,C) wird jeweils die Sicherheitsinformation (P1) mit Hilfe der
Exklusiv-Oder-Verknüpfung berechnet. Diese Information wird nun allerdings nicht mehr
auf eine bestimmte Festplatte geschrieben, sondern abwechselnd auf alle Platten verteilt
wie beim Data-Striping. Bei parallel schreibendem Zugriff auf kleine Datenblöcke werden
in einem RAID-5-Verband alle Festplatten gleichmäßig belastet. Hierdurch kann die Gesamt-Performance des Systems gesteigert werden.
Der RAID-Level 6 berücksichtigt dieses Problem und löst es durch eine
Kombination aus dem Level 5 und einem kleinen Rückschritt auf die Level
3 und 4. Neben den Nutz- und Paritätsdaten des Level 5 wird nun wieder
wieder ein eigener Datenträger für eine zusätzliche Paritätsinformation
eingesetzt. Damit wird erreicht, daß selbst bei Totalausfall einer Platte die Daten
zurückgewonnen werden können.
Ähnlich wie RAID-5 schreibt RAID-7 in Datenblöcken. Hier läuft auf dem Controller ein
zusätzliches lokales Betriebssystem in Echtzeit. ES werden mehrere Swap-Partitionen
auf den Laufwerken sowie schnelle Datenbusse verwendet, die von der Datenübertragung
entkoppelt sind. Damit beschleunigt RAID-7 den Datentransfer erheblich. Die
Paritätsinformationen werden wie bei RAID-6 zusätzlich auf separate Datenträger
geschrieben.
Bei RAID-10 (auch RAID-0+1) handelt es sich um eine Kombination der Vorteile
von RAID-0 und RAID-1. Bei RAID-10 werden mehrere RAID-1-Spiegelverbände
zusammengefasst (STRIPING). Die Performance ist erheblich, da keine
Paritätsinformationen errechnet werden müssen und so die volle
Datenübertragungsrate von Laufwerken und Bus zur Verfügung stehen.
RAID-10 wird daher oft zum Speichern sehr großen Dateien mit hohen
Anforderungen an Performance und Redundanz verwendet. Durch den Einsatz von
mindestens vier Festplatten entstehen allerdings recht hohe Kosten.
RAID-51 (auch RAID-15) ist die nächste Kombination. Sie besteht aus RAID-5
und RAID-1. Dabei werden RAID-5-Verbände zusätzlich gespiegelt. Die Performance
sinkt gegenüber RAID-5 nicht, es wird aber höhere Datensicherheit geboten.
Ein RAID-Level für hochkritische Sicherheitserfordernisse.
Die Abhängigkeiten zwischen RAID-Level, Performance und Ausfallsicherheit faßt
die folgende Tabelle noch einmal zusammen. Wie sich deutlich erkennen läßt,
bringt jedes der RAID-Verfahren spezifische Vor- und Nachteile.
| RAID-Level im Vergleich
|
| |
RAID 0 |
RAID 1 |
RAID 10 |
RAID 2 |
RAID 3 |
RAID 4 |
RAID 5 |
| Anzahl Laufwerke |
n > 1 |
n = 2 |
n > 3 |
N = 10 |
n > 2 |
n > 2 |
n > 2 |
| Redundante Laufwerke |
0 |
1 |
1(**) |
2 |
1 |
1 |
1 |
| Kapazitätsoverhead (Prozent) |
0 |
50 |
50 |
20 |
100/n |
100/n |
100/n |
| Parallele Leseoperationen |
n |
2 |
n / 2 |
8 |
n - 1 |
n - 1 |
n - 1 |
| Parallele Schreiboperationen |
n |
1 |
1 |
1 |
1 |
1 |
n /2 |
| Maximaler Lesedurchsatz (*) |
n |
2 |
n / 2 |
8 |
n - 1 |
n - 1 |
n - 1 |
| Maximaler Schreibdurchsatz (*) |
n |
1 |
1 |
1 |
1 |
1 |
n/2 |
Zusammenfassung:
- Redundanz aufbauen
(mehrere Server, redundante Komponenten: Platte, Netzteil, Netzwerkkarte,
- Server überwachen (Antwortzeit, Funktion, Temperatur, etc.)
- Fehlerquelle Systemadministrator, Webmaster, Putzfrau, Hausmeister
nicht vergessen
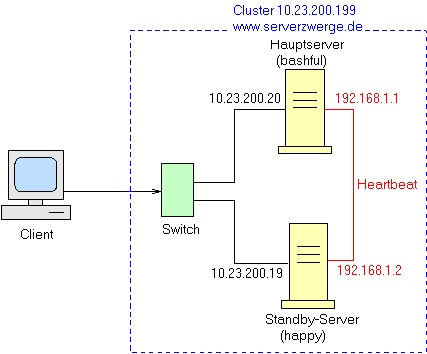
Beispiel: Warm-Standby mit heartbeat
In einer Warm-Standby-Konfiguration wird ein Server durch ein
zweites System ergänzt, daß im Fehlerfall einspringen kann.
Aktiv ist immer nur einer der beiden Rechner: Im Normalfall der Hauptserver,
im Fehlerfall der Standby-Rechner. Der jeweils aktive Rechner erhält
die Cluster-IP-Nummer zugewiesen, unter der der hochverfügbare
Dienst zu Verfügung stehen soll.
Dazu ein Beispiel:
Der Webserver www.serverzwerge.de mit der Adresse 10.23.200.199 soll hochverfübar gemacht werden.
Diese Adresse bezeichnen wir im Folgenden als Cluster-Adresse.
Zunächst einmal benötigen wir einen Server, der den Dienst im
Normalfall zur Verfügung stellt. Im Beispiel ist das der Rechner bashful.
Die Rolle des Standbysystems übernimmt happy.
Beide Maschinen werden zunächst normal installiert und konfiguriert.
Sie erhalten dazu je eine IP-Adresse, die in unserem Beispiel aus dem Subnetz
10.23.200.0 stammt.
Wichtig ist dabei, daß keiner von beiden die Cluster-IP-Nummer bekommt.
In der normalen Netzwerkkonfiguration von happy und bashful
taucht sie nicht auf; sie wird erst innerhalb der Konfigurationsdateien
von heartbeat festgelegt.
Damit der Standby-Rechner weiß, wann der Hauptserver ausgefallen ist,
muß er immer ein "Lebenszeichen" von ihm empfangen. Bleibt dieses
Heartbeatsignal aus, dann ist von einem Ausfall des Servers auszugehen.
Der Austausch dieser Heartbeatsignale geschieht auf einer eigenen Leitung. Dazu kann
man ein Nullmodemkabel an der seriellen Schnittstelle, oder ein Crosslinkkabel
und je eine zweite Netzwerkkarte verwenden. In unserem Beispiel verwenden wird die
letztere Möglichkeit. Jede dieser Netzwerkkarten braucht natürlich
auch eine IP-Nummer. Im Beispiel wurden die Adressen 129.168.1.1 und
192.168.1.2 verwendet. Da es sich um einen Direktverbindung via
Crosslinkkabel handelt brauchen die beiden Rechner auch keinen
zwischengeschalten Netzwerkverteiler wie Hub oder Switch.
Bei einer Debian-Distribution sähe die Netzwerkkonfiguration von bashful
über die Datei /etc/network/interfaces so aus:
auto lo
iface lo inet loopback
auto eth0
iface eth0 inet static
address 10.23.200.20
netmask 255.255.0.0
broadcast 10.23.255.255
gateway 10.23.64.1
auto eth1
iface eth1 inet static
address 192.168.1.1
netmask 255.255.255.0
broadcast 192.168.1.255
Bei anderen Distributionen funktiniert das ähnlich. Nun muß man das
Netzwerk neu starten mit /etc/init.d/network restart
Anschliessend kann man mit ifconfig -a nachschauen, ob alles
ok ist. Die Ausgabe müßte dann etwa wie folgt aussehen:
eth0 Link encap:Ethernet HWaddr 00:04:75:89:3A:80
inet addr:10.23.200.20 Bcast:10.23.255.255 Mask:255.255.0.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:11373 errors:0 dropped:0 overruns:1 frame:0
TX packets:1822 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:100
RX bytes:1447128 (1.3 MiB) TX bytes:1725729 (1.6 MiB)
Interrupt:11 Base address:0xcc00
eth1 Link encap:Ethernet HWaddr 00:D0:B7:80:E0:B1
inet addr:192.168.1.1 Bcast:192.168.1.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:10539 errors:0 dropped:0 overruns:0 frame:0
TX packets:10539 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:100
RX bytes:1639202 (1.5 MiB) TX bytes:1649556 (1.5 MiB)
Interrupt:9 Base address:0xc000
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:54 errors:0 dropped:0 overruns:0 frame:0
TX packets:54 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:3748 (3.6 KiB) TX bytes:3748 (3.6 KiB)
Nach der Installation des Heartbeat-Paketes von http://www.linux-ha.org/ kann es mit der Konfiguration losgehen. Die zugehörigen
Dateien werden im Verzeichnis /etc/ha.d abgelegt.
Als erstes muß die Datei ha.cf editiert werden. bashfuls Datei
lautet:
# File to wirte debug messages to
debugfile /var/log/ha-debug
#
# File to write other messages to
#
logfile /var/log/ha-log
#
# Facility to use for syslog()/logger
#
logfacility local0
#
#
# keepalive: how many seconds between heartbeats
keepalive 2
#
# deadtime: seconds-to-declare-host-dead
deadtime 10
#
#
# Very first dead time (initdead)
#
# On some machines/OSes, etc. the network takes a while to come up
# and start working right after you've been rebooted. As a result
# we have a separate dead time for when things first come up.
# It should be at least twice the normal dead time.
initdead 40
#
# serial serialportname ...
#serial /dev/ttyS0
#
# Baud rate for serial ports...
baud 19200
#
# What UDP port to use for communication?
udpport 694
#
# What interfaces to heartbeat over?
#
udp eth1
#
node bashfull
node happy
Dabei ist:
| debugfile | Datei, in die Debugmeldungen geschrieben werden |
| logfile | Logdatei, die den Status des jeweiligen Knotens anzeigt |
| logfacility | In welchen Kanal soll syslog schreiben? |
| keepalive | Zeit zwischen zwei Heartbeatsignalen in Sekunden |
| deadtime | Wenn für diese Zeit kein Heartbeatsignal vom anderen Knoten eintrifft, wird er für tot erklärt. |
| initdead | Erste Wartezeit nach dem Booten eines Systemes. Damit läßt man dem Knoten Zeit, nach dem Booten alle seine Dienste zu starten und
sein Netzwerk zu iniialisieren. Ist nach dieser Spanne kein Heartbeat vom System zu hören, wird es als tot eingestuft. |
| serial | Bei serieller Heartbeatverbindung: Port, an dem das Kabel angeschlossen ist. Z.B.: /dev/ttyS0 |
| baud | Bei serieller Heartbeatverbindung: Baudrate. Z.B.: 19200 |
| udpport | UDP-Port auf dem die Kommunikation stattfinden soll. Z.B.: 694 |
| udp | Interface der Heartbeatleitung. Z.B.: eth1 für die zweite Ethernet-Netzwerkkarte im System |
| node | Name eines beteiligten Rechnerknotens. Je eine Zeile pro Rechner. |
Nachdem heartbeat die Übertragung der Lebenszeichen nicht
nur auf exklusiven, sondern auch auf anderweitig benutzten Leitungen zuläßt, besitzt es verschiedene Moeglichkeiten, den Heartbeat-Datenstrom zu verschlüsseln. Welches Verfahren verwendet wird, legt die Datei /etc/ha.d/authkeys
fest. Hier kann man aus drei Verfahren wählen: CRC-Checksumme, SHA1- oder MD5- Verschlüsselung. Verwendet man ein Crosslink oder ein serielles
Kabel, dann sollte man CRC auswählen. Bei einem, gemeinsam mit anderen Rechnern
genutzten Ethernetstrang, wählt man eines der Verschlüsslungsverfahren.
SHA1 ist das rechnenintensivste. Sowohl bei SHA1 als auch bei MD5 mauß man
zusätzlich einen Authentifizierungsschlüssel, also so eine Art Paßwort,
angeben. Das Format von /etc/ha.d/authkeys ist:
auth Nummer
Nummer Authentifizierungsmethode Schlüssel
Bei CRC also:
auth 1
1 CRC
Und bei MD5:
auth 1
1 MD5 Mein-geheimer-Schluessel
Nun steht fest, wie die beiden Clustermaschinen verbunden sind und über welches Interface sie kommunizieren sollen.
Aber es ist noch nicht geklärt, welcher der Rechner der Hauptserver
und welche Dienste hochverfügbar sein sollen. Diese Aufgabe übernimmt
die Datei /etc/ha.d/haressources.
In unserem Beispiel enthält sie lediglich die Zeile
bashful 10.23.200.199 apache
Dabei ist:
| bashful | Name des Hauptservers |
| 10.23.200.199 | IP-Nummer, unter der der Clusterdienst laufen soll. |
| apache | Name des Skriptes in /etc/init.d/ das auf dem jeweils aktiven Knoten gestartet werden soll. |
Alle beschriebenen Datei werden nun in das Verzeichnis /etc/ha.d/
des anderen Clusterknotens kopiert. Damit ist das Warm-Standy-Cluster startbereit.
Ein Aufruf von /etc/init.d/heartbeat start auf beiden
Konoten aktiviert das Cluster. Mit dem Kommando tail -f /var/log/ha-log
läß:t sich kontrollieren, wie der Status des Systems ist. In
unserem Beispielcluster liefert bashful nach dem Start die Ausgabe:
heartbeat: 2003/02/11_09:33:42 info: **************************
heartbeat: 2003/02/11_09:33:42 info: Configuration validated. Starting heartbeat 0.4.9.0l
heartbeat: 2003/02/11_09:33:43 info: heartbeat: version 0.4.9.0l
heartbeat: 2003/02/11_09:33:43 info: Heartbeat generation: 11
heartbeat: 2003/02/11_09:33:43 info: Creating FIFO /var/run/heartbeat-fifo.
heartbeat: 2003/02/11_09:33:43 notice: UDP heartbeat started on port 694 interface eth1
heartbeat: 2003/02/11_09:33:43 info: Local status now set to: 'up'
heartbeat: 2003/02/11_09:33:45 info: Heartbeat restart on node bashful
heartbeat: 2003/02/11_09:33:45 info: Link bashful:eth1 up.
heartbeat: 2003/02/11_09:33:45 info: Local status now set to: 'active'
heartbeat: 2003/02/11_09:33:45 info: Heartbeat restart on node happy
heartbeat: 2003/02/11_09:33:45 info: Link happy:eth1 up.
heartbeat: 2003/02/11_09:33:45 info: Node happy: status active
heartbeat: 2003/02/11_09:33:45 info: Node bashful: status up
heartbeat: 2003/02/11_09:33:45 info: Running /etc/ha.d/rc.d/ifstat ifstat
heartbeat: 2003/02/11_09:33:45 info: Running /etc/ha.d/rc.d/status status
heartbeat: 2003/02/11_09:33:45 info: Running /etc/ha.d/rc.d/ifstat ifstat
heartbeat: 2003/02/11_09:33:45 info: Running /etc/ha.d/rc.d/status status
heartbeat: 2003/02/11_09:33:45 info: Running /etc/ha.d/resource.d/IPaddr 10.23.200.199 status
heartbeat: 2003/02/11_09:33:45 info: Node bashful: status active
heartbeat: 2003/02/11_09:33:45 info: Resource acquisition completed.
heartbeat: 2003/02/11_09:33:45 info: Running /etc/ha.d/rc.d/status status
heartbeat: 2003/02/11_09:33:45 info: Running /etc/ha.d/rc.d/ip-request ip-request
heartbeat: 2003/02/11_09:33:55 info: Running /etc/ha.d/resource.d/IPaddr 10.23.200.199 status
heartbeat: 2003/02/11_09:33:55 info: Acquiring resource group: bashful 10.23.200.199 apache
heartbeat: 2003/02/11_09:33:55 info: Running /etc/ha.d/resource.d/IPaddr 10.23.200.199 start
heartbeat: 2003/02/11_09:33:56 info: ifconfig eth0:0 10.23.200.199 netmask 255.255.0.0 broadcast 10.23.255.255
heartbeat: 2003/02/11_09:33:56 info: Sending Gratuitous Arp for 10.23.200.199 on eth0:0 [eth0]
heartbeat: 2003/02/11_09:33:56 info: Running /etc/init.d/apache start
Deutlich ist dabei die Funktionsweise von heartbeat zu sehen:
Zunächst wird die Konifiguration überprüft und dann
die Cluster-IP auf das Netzwerkinterface gebunden. Das geschieht durch erzeugen
eines virtuellen Devices (z.B. eth0:0). Das Kommando ifconfig -a
liefert nun zusätzlich den Eintrag, wie im folgenden Beispiel:
eth0:0 Link encap:Ethernet HWaddr 00:04:75:89:3A:80
inet addr:10.23.200.199 Bcast:10.23.255.255 Mask:255.255.0.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
Interrupt:11 Base address:0xcc00
Anschliessend sendet der aktive Knoten eine Broadcastmeldung an alle Rechner
im Netz und fordert sie auf ihre ARP-Caches zu leeren. Damit stellt er sicher,
das alle zugreifenden Clients, bei Übernahme des Dienstes durch einen
enderen Knoten, ihre IP-Nummer/Ethernetzuordnung im ARP-Cache löschen
und mit den Daten des neuen Knotens überschreiben.
Zum Schluß wird der hochverfügbare Dienst gestartet. In unserem Fall ist
das lediglich das Skript /etc/init.d/apache.
Die Aktivierung der Cluster-IP-Nummer kann nun mit einem einfachen ping-Kommando
kontrolliert werden. An einem beliebigen Client gibt man ein:
ping 1023.200.199
Darauf sollte das Cluster antworten. Hat das funktioniert, dann kann man
den hochverfügbaren Dienst testen. Im Beispiel könnte man also
im Webbrowser https://10.23.200.199 eingeben un erhält
die Startseite des Webservers.
Als letztes sollte man natürlich die einwandfreie
Umschaltung des Dienstes zwischen den Rechnerknoten testen. Dazu
fährt man den Hauptserver mit dem Kommando
reboot herunter und wieder rauf. Gleichzeitig
kann man mit tail -f /var/log/ha-log am Standbyknoten
zuschauen, wie die Cluster-IP-Adresse übernommen und der Serverdienst
auf dem bisher inaktiven Knoten aktiviert wird.
Ein dauerhaftes ping auf die Cluster-IP-Nummer zeigt, das der Cluster
städig erreichbar ist; auch während der Hauptserver ausfällt.
|
|
|
