 |
aufgelistet (Urliste). Aus dieser Stichprobe vom
Umfang n kann man Schlüsse auf die zugehörige Grundgesamtheit N
ziehen. Wären gleichzeitig mehrere Merkmale gemessen worden, z. B.
Masse und Größe, so hätte man eine Stichprobe erhalten,
die aus n Zahlenpaaren besteht.
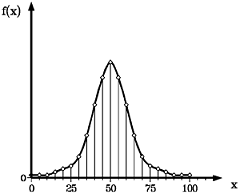 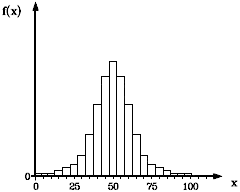
Häufigkeitsverteilung einer Gaußschen Normalverteilung.
links: Stabdiagramm, Häufigkeitspolygon, rechts: Balkendiagramm
Bei kleinen Stichproben hilft es schon, wenn man die Werte der Größe
nach ordnet, um einen Überblick zu bekommen. Besser ist es, zahlenmäßig
gleiche Werte zusammenzufassen und sie graphisch darzustellen. Dabei wird
die Anzahl ai über dem Meßwert xi aufgetragen.
Die Anzahl ai heißt die absolute Häufigkeit des betreffenden
Wertes in der Stichprobe. Dividiert man die absolute Häufigkeit durch
den Stichprobenumfang n, so erhält man die relative Häufigkeit.
Die relative Häufigkeit ist somit immer eine Zahl zwischen 0 und 1.
Die Auftragung kann als Punkt-, Stab- oder Balkendiagramm erfolgen. Eine
direkte Verbindung der Punkte untereinander ergibt ein Häufigkeitspolygon.
Diese Graphiken stellen Häufigkeitsverteilungen oder Histogramme der
Stichprobe dar.
Die folgende Funktion drucht ein Histogramm für bis zu 25 Häfigkeiten,
die im Array h gespeichert sind (int werte[25]). Dabei werden die Balken
auf maximal 20 Zeilen normiert. Der erste Parameter der Funktion übergibt eine
Überschrift, der zweite Parameter ist das oben erwähne Wertearray und der
dritte Parameter gibt an, wieviele Balken auszugeben sind.
void make_histo(char *headline, int werte[], int n)
{
int h[25];
int i, j, max = 0;
for (i = 0; i <= n; i++) /* Maximum finden */
if (werte[i] > max) max = werte[i];
for (i = 0; i <= n; i++) /* Normieren */
h[i] = werte[i]*20/max;
printf("\n%s\n",headline);
printf(" |");
for (i = 0; i <= n; i++) /* oberste Zeile */
if (h[i] >= 20) printf("%2d ",h[i]);
else printf(" ");
printf("\n ");
for(j = 19; j >= 1; j--) /* y-Achse */
{
printf("|");
for (i = 0; i <= n; i++) /* x- Werte */
if (h[i]>=j) printf(" * ");
else printf(" ");
printf("\n ");
}
for (i = 0; i <= n; i++) /* x-Achse zeichnen */
printf("%s","--+");
printf("\n ");
for (i = 0; i <= n; i++) /* x-Achse beschriften */
printf("%3d",i);
printf("\n");
}
Für die Statistische Auswertung eines Feldes mit Urdaten müssen
zuerst die Häfigkeiten ermittelt werden. Dazu dient die folgende Funktion.
Die Häfigkeiten werden in einem Feld "hauf" gespeichert, dessen
Komponenten den Datenwert und seine Häufigkeit speichern. Deshalb
sind die Feldkomponenten ein Verbund:
struct Counter { double value; int count; };
Das Datenfeld muß aufsteigend sortiert vorliegen. Dazu wird die
Bibliotheksfunktion qsort verwendet, die ihrerseits eine
Vergleichsfunktion benötigt. Ein Aufrufbeispiel finden
Sie weiter unten.
int dblvgl(const double *v1, const double *v2)
/* Vergleich zweier double-Werte (fuer Sortierung) */
{
if (*v1 > *v2) return(1);
if (*v1 < *v2) return(-1);
return (0);
}
void frequencies(double data[], int n, struct Counter hauf[], int *toph)
/* Zaehlt die Haeufigkeiten der Werte in data */
/* 'n' gibt die Anzahl der uebergebenen Werte an */
/* Rueckgabe: hauf: (Werte und zugeh. Haeufigk.), */
/* toph: letzter verwendeter Index von hauf */
/* Seiteneffekt: SOrtieren des Datenfeldes */
/* struct Counter { double value; int count; }; */
{
int i, k;
k = 0;
qsort(data, n, sizeof(data[0]), dblvgl);
hauf[0].count = 1;
hauf[0].value = data[0];
for (i = 1; i < n; i++)
{
if (data[i] == data[i-1])
hauf[k].count++;
else
{
k++;
hauf[k].count = 1;
hauf[k].value = data[i];
}
}
*toph = k;
}
Um die nun ermittelten Häfigkeiten auszugeben, kann man ein
waagrecht liegendes Histogramm drucken. Dies leistet die folgende Funktion.
void printfrequencies(struct Counter hauf[], int n)
/* Ausgabe Histogramm der Haeufugkeiten in hauf */
/* 'n' gibt die Anzahl der uebergebenen Werte an */
/* struct Counter { double value; int count; }; */
{
int i, k, max;
max = 0;
/* maximum der Haeufigkeiten ermitteln */
for (i = 0; i <= n; i++)
if (hauf[i].count > max) max = hauf[i].count;
/* Ausgabe */
for (i = 0; i <= n; i++)
{
printf("%12lf: ", hauf[i].value);
for (k = 0; k < hauf[i].count*50/max; k++)
putchar('#');
printf(" (%5d)\n",hauf[i].count);
}
}
Mittelwert, Varianz, Standardabweichung, Standardfehler
Neben der Häufigkeitsfunktion kann man eine Grundgesamtheit oder eine
Stichprobe auch durch Maßzahlen charakterisieren. Die beiden in der Praxis
wichtigsten Maßzahlen sind der Mittelwert, der die durchschnittliche
Größe der Grundgesamtheit N oder der Stichprobe n kennzeichnet, und eine
Angabe über die Streuung der Werte. Im weiteren wird von der Annahme
ausgegangen, daß die Meßwerte eine Normalverteilung nach Gauß
ergeben. Eine genügend große Stichprobe wird vorausgesetzt. Der
arithmetische Mittelwert ist definiert als:
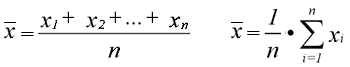
µ = Mittelwert der Grundgesamtheit,
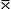 = Mittelwert der Stichprobe = Mittelwert der Stichprobe
Die folgende Funktion berechnet den Mittelwert eines double-Arrays.
Als Parameter werden dieses Array und die Anzahl der relevanten Elemente im Array
übergeben (der Index läuft dnn von 0 bis n-1).
double mittel(double data[], int n)
/* Mittelwert des Arrays 'data' */
/* 'n' gibt die Anzahl der uebergebenen Werte an */
{
int i;
double sum;
sum = 0.0;
for (i = 0; i < n; i++)
sum += data[i];
return(sum/(double)n);
}
Dieser allein reicht jedoch nicht aus, um z. B. eine Stichprobe zu beschreiben,
wie folgendes Beispiel zeigt:
Stichprobe 1: 1.5, 3.0, 3.5, 4.0 -> = 3
Stichprobe 2: 2.8, 2.9, 3.1, 3.2 -> = 3
Beide Stichproben haben den Mittelwert = 3.
Sie unterscheiden sich aber trotzdem wesentlich voneinander, denn die
Werte der ersten Stichprobe liegen viel weiter auseinander (und auch weiter
vom Mittelwert entfernt) als die Werte der zweiten Stichprobe. Um diesen
Unterschied zu erfassen, braucht man noch eine weitere Maßzahl. Geeignet
ist hierzu offenbar eine Zahl, die die Abweichung der Stichprobenwerte
vom Mittelwert mißt. Man könnte die Spannweite der Stichprobe,
d. h. die Differenz zwischen dem größten (Maximum) und kleinsten
(Minimum) Stichprobenwert ermitteln. Es wird jedoch gefordert, daß
ähnlich wie beim Mittelwert jeder Einzelwert in gewisser Weise
mitberücksichtigt wird. Die wohl nächstliegende Möglichkeit,
die Summe der Einzelabweichungen xi - .
scheidet allerdings aus, da die Summe aus negativen und positeven Gliedern
besteht und diese somit immer Null ist. Dies könnte vermieden werden,
wenn man die Absolutbeträge der Einzelabweichungen bilden würde.
Aus mathematischen Ableitungen hat sich jedoch die Bildung der Quadrate
der Einzelabweichungen als günstiger erwiesen. Diese werden auch als
die kleinsten Gaußschen Fehlerquadrate (engl. least square) bezeichnet.
Die Maßzahl, die man auf diesem Weg erhält heißt Varianz
oder Streuung (engl. variance). Sie berechnet sich für die
Grundgesamtheit zu
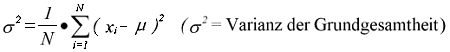
und für die Stichprobe zu
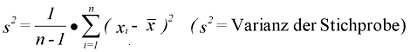
Aus der Wahrscheinlichkeitstheorie läßt sich die unterschiedliche
Berechnung der Varianz für Grundgesamtheit und Stichprobe ableiten.
Man muß im allgemeinen bei der Berechnung nur wissen, ob es sich
um eine Grundgesamtheit oder eine Stichprobe handelt. (n - 1) bezeichnet
man als die Anzahl der Freiheitsgrade, sie ergeben sich aus der Anzahl
unabhängiger Einzelwerte. Die nichtnegative Quadratwurzel der Varianz
heißt Standardabweichung (engl. standard deviation, S.D.)
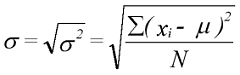
Standardabweichung der Grundgesamtheit
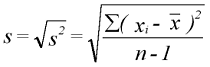
Standardabweichung der Stichprobe
Die Größen
Varianz und Standardabweichung sind mit demselben Formelbuchstaben belegt,
da beide in der Praxis gleichwertig verwendet werden. Die Varianz hat den
Vorteil, daß man sich nicht mit Quadratwurzeln herumärgern muß.
Die Standardabweichung hat den Vorteil, daß sie dieselbe Dimension
der Größeneinheit (z. B. cm oder kg) wie der Mittelwert besitzt.
Für die obigen Beispiele ergeben sich somit:
Stichprobe 1: = 3, s2 = 1.17, s = 1,08
Stichprobe 2: = 3, s2 = 0,03, s = 0,18
Die Streuung der zweiten Stichprobe ist also wesentlich kleiner. Durch
Angabe von Mittelwert und Varianz bzw. Standardabweichung sind Stichproben
meist ausreichend beschrieben.
Die Berechnung der Standardabweichung (bzw. Varianz) nach den Definitionsformeln
ist jedoch numerisch ungünstig. Durch die Differenzbildung (xi - x) von den relativ
großen Zahlen entstehen sehr kleine Differenzen, die dann auch noch quadriert
werden müssen. Durch Rundungsfehler entstehen Genauigkeitsverluste. Es gibt deshalb
Berechnungsformeln für die Praxis. Bei ihnen werden die Differenzbildungen
vermieden. Für die Standardabweichung einer Stichprobe ergibt sich somit
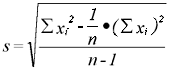 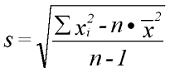
Die Funktion varianz hat die gleichen Parameter, wie die Mittelwert-Funktion.
Es werden in der Schleife gleichzeitig Summe und Quadratsumme berechnet und
anschließend die Varianz.
double varianz(double data[], int n)
/* Varianz des Arrays 'data' */
/* 'n' gibt die Anzahl der uebergebenen Werte an */
{
int i;
double sum, sumsq;
sum = 0.0;
sumsq = 0.0;
for (i = 0; i < n; i++)
{
sum += data[i]; /* Summe */
sumsq += (data[i] * data[i]); /* Summer der Quadrate */
}
return((sumsq - sum*sum/(double)n)/(double)(n - 1));
}
Bei der Bestimmung von Stichproben möchte man auch gerne wissen, mit
welcher Wahrscheinlichkeit von den bei einer Stichprobe gefundenen Größen
auf die Grundgesamtheit geschlossen werden kann. Die für
eine Stichprobe ermittelten Werte (Mittelwert, Varianz, Standardabweichung)
sind also nur Schätzwerte für die Grundgesamtheit. Man möchte
z. B. wissen, wie weit der Stichprobenmittelwert
vom Mittelwert der Grundgesamtheit µ abweicht. Diese Abweichung bezeichnet
man als Standardfehler (= Fehler des Mittelwertes = Standardabweichung
des Mittelwertes; engl. standard error of the mean, S.E.). Wenn keine extremen
Abweichungen der Stichprobenwerte xi von der Normalverteilung
um den Stichprobenmittelwert vorliegen,
darf man annehmen, sich daß auch die Mittelwerte annähernd gleich
großer Stichproben gleichmäßig um den Grundgesamtheitsmittelwert
µ verteilen. Die unbekannte wirkliche Abweichung s
kann durch den Standardfehler s
abgeschätzt werden. Er berechnet sich aus der Standardabweichung s.
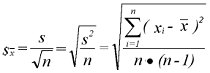
Das zusätzliche "n" in der Formel für den Standardfehler s (im
Gegensatz zu Varianz und Standardabweichung) liefert eine Angabe über
die Größe der Stichprobe. Je größer eine Stichprobe
ist, desto genauer wird die Schätzung für die Grundgesamtheit.
Der Standardfehler verkleinert sich dabei (n steht im Nenner), geht
somit gegen µ.
Die C-Funktion dazu ist trivial - sie berechnet lediglich die Quadratwurzel
der oben gezeigten Varianz-Funktion:
double streuung(double data[], int n)
/* Streuung des Arrays 'data' */
/* 'n' gibt die Anzahl der uebergebenen Werte an */
{
return(sqrt(varianz(data,n)));
}
Der Standardfehler wird oft zusammen mit dem Stichprobenmittelwert zur
Charakterisierung einer Stichprobe bezüglich der Grundgesamtheit angegeben:
± s (z. B. 5 g ± 0,6 g)
Minimum, Maximum, Median, Modalwert
Minimum ist der kleinste, Maximum der größte im Array
vorkommnde Wert.
Der Zentralwert oder Medianwert stellt ebenfalls einen charakteristischen
Wert einer Häufigkeitsverteilung dar. Er wird für bestimmte statistische
Verfahren benötigt. Er teilt die Häufigkeitsverteilung flächengleich
auf, so daß sich links und rechts vom Zentralwert genau gleich viele
Ereignisse befinden.
Der häufigste Wert oder Modalwert stellt, wie sein Name schon
sagt, den Wert mit der größten Häufigkeit dar. Er ist also
der Gipfel ("Peak") in einer Häufigkeitsverteilung. In einer Normalverteilung
sind infolge der Symmetrie der Verteilung arithmetischer Mittelwert, Medianwert und
Modalwert identisch. Er kann mit Hilfe der weiter oben vorgestellten Funktion
frequencies ermittelt werden.
Die Funktion zum Berechnen der anderen Werte muß das Datenfeld sortieren
(speziell für den Median). Dazu wird die Bibliotheksfunktion qsort
verwendet, die ihrerseits eine Vergleichsfunktion benötigt. Die statistischen
Werte gibt die Funktion als Refernzparameter zurück. Ein Aufrufbeispiel finden
Sie weiter unten.
int dblvgl(const double *v1, const double *v2)
/* Vergleich zweier double-Werte (fuer Sortierung) */
{
if (*v1 > *v2) return(1);
if (*v1 < *v2) return(-1);
return (0);
}
void minimax(double data[], int n,
double *min, double *max, double *median)
/* Minimum, Maximum und Median des Arrays 'data' */
/* 'n' gibt die Anzahl der uebergebenen Werte an */
/* Rueckgabe: min, max, median */
/* (data ist anschliessend sortiert) */
{
qsort(data, n, sizeof(data[0]), dblvgl);
*min = data[0];
*max = data[n-1];
if ((n % 2) == 0) /* n gerade */
*median = (data[(n-1)/2] + data[(n-1)/2+1])/2;
else
*median = data[(n-1)/2+1];
}
Aufrufbeispiele
Das folgende Hauptprogramm zeigt, wie man die oben aufgeführten Funktionen
aufruft. Der Einfachheit halber wirde das Datenfeld statisch vorbelegt, bei
einer realen ANwendung wird man die Daten sicher von einer Datei einlesen.
int main(void)
{
double Data[MAXDATA] = {1.5, 2.0, 1.5, 3.0, 2.5, 1.5, 2.0, 2.5, 3.5, 3.0};
struct Counter Hauf[MAXDATA];
double min, max, median;
int toph;
printf("Mittel: %lf Varianz: %lf Streuung: %lf\n",
mittel(Data,10), varianz(Data,10), streuung(Data,10));
minimax(Data,10, &min, &max, &median);
printf("Minimum: %lf Maximum: %lf Median: %lf Spanne: %lf\n",
min, max, median,max-min);
frequencies(Data,10,Hauf,&toph);
printfrequencies(Hauf,toph);
return(0);
}
Die Ausgabe des Programms sieht folgendermaßen aus:
Mittel: 2.300000 Varianz: 0.511111 Streuung: 0.714920
Minimum: 1.500000 Maximum: 3.500000 Median: 2.250000 Spanne: 2.000000
1.500000: ################################################## ( 3)
2.000000: ################################# ( 2)
2.500000: ################################# ( 2)
3.000000: ################################# ( 2)
3.500000: ################ ( 1)
Gaußverteilung, Poissonverteilung
Als Beispiele für theoretische, stetige Häufigkeitsverteilungen
sollen die Normalverteilung (Gaußsche Glockenkurve) und die Poissonverteilung
als Beispiel für eine schiefe Verteilung besprochen werden. Viele
Meßwerte aus Experimenten sind nach diesen beiden theoretischen Mustern
verteilt. Die Normalverteilung wurde von Gauß im Zusammenhang mit der Theorie
der Meßfehler eingeführt. Aus verschiedenen Gründen ist
sie die wichtigste stetige Verteilung:
- Viele Zufallsvariablen, die bei Experimenten und Beobachtungen auftreten,
sind normalverteilt.
- Andere Zufallsvariable sind annähernd normalverteilt. In vielen
Fällen führt dann die Annahme einer Normalverteilung zu sinnvollen
und praktisch brauchbaren Ergebnissen.
- Gewisse, nicht normalverteilte Variablen lassen sich so transformieren,
daß die sich daraus ergebende Variable normalverteilt ist.
Die Funktionsgleichung der Gaußverteilung lautet:
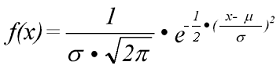
Die Standardabweichungen ± s sind definitionsgemäß die
Wendepunkte der Glockenkurve, projeziert auf die x-Achse.
- Im Bereich zwischen ±s liegen 68 % aller beobachteten Werte.
- Im Bereich ±2s liegen 95,5 % aller beobachteten Werte.
- Im Bereich ±3s liegen 99,7% aller beobachteten Werte.
Die Standardabweichung s ist ein Maß für die Streuung der Werte um den
Mittelwert µ. Je größer die Standardabweichung, desto weiter
streuen also die Werte um den Mittelwert µ. Die Summenhäufigkeitsfunktion
oder Verteilungsfunktion (Integral der Glockenkurve) ergibt eine Sigmoide.
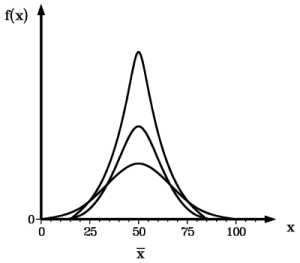
Normalverteilungen mit gleich
großen Mittelwerten und verschieden großen Standardabweichungen
Ein Beispiel für eine schiefe stetige Verteilung ist die Poissonverteilung
mit der Funktionsgleichung:
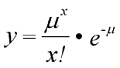
Für Mittelwerte nahe Null kann sich die Poissonverteilung einer
abnehmenden Exponentialfunktion nähern, für größere
Mittelwerte kann sie in eine Normalverteilung übergehen.
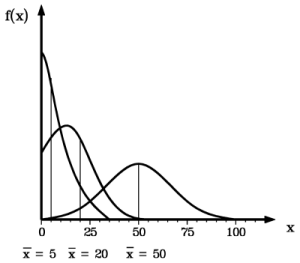
= 5 -> Annäherung an negative Exponentialfunktion
= 50 -> Annäherung an Normalverteilung
Lineare Regression
Bei der Erfassung von Meßgrößen besteht oft der Wunsch,
Werte zwischen den einzelnen Stützpunkten zu ermitteln. Hier helfen
Interpolation und Regression.
Bei der linearen Interpolation wird die Näherung eines Funktionswerts
f(x) mit x1 < x < x2 aus den bekannten
Funktionswerten f(x1) und f(x2) gewonnen.
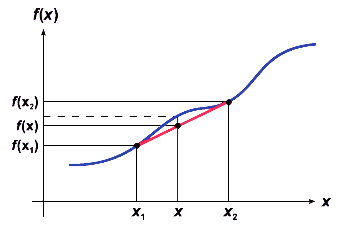
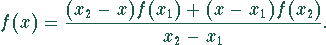
Sind von einer Funktion nur die Werte an den Stützstellen x1,
x2, ..., xn bekannt, so läßt sich durch
Interpolation eine stückweise lineare Funktion definieren.
Bei der linearen Regression wird eine Gerade ax + b
gesucht. Diese Gerade wird in einer bestmöglichen Näherung in eine
Auftragung von n Datenpunkten (x1, f(x1)),
(x2, f(x2)), ... ,(xn, f(xn))
gelegt.
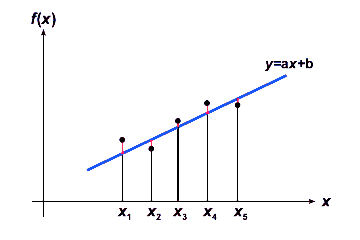
Die bestmögliche Anpassung ist gegeben, wenn die Summe der Abweichungsquadrate
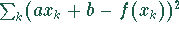
minimal wird. Die Werte von a und b errechnen sich aus den
Gleichungen
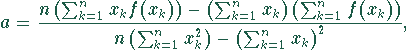
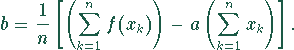
Im folgenden Programm wird a in die Formel für b eingesetzt - daher sieht es
etwas anders aus. Zudem werden nicht nur die Parameter a und b errechnet, sondern auch
zwei statistische Maßzahlen, welche es erlauben, die "Güte" der
Regressionsgeraden zu beurteilen. es sind dies die mittlere quadratische Abweichung
der Geraden von allen Stützpunkten und die Standardabweichung für a und b.
Im Testprogramm wurden die Funktionswerte von y = 2a + 2 leicht verändert.
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
int linreg (double x[], double y[], int anz,
double *a, double *b,
double *r, double *sa, double *sb)
/* Lineare Regression fuer 'anz' Stuetzpunkte (x[i], y[i]):
* Rueckgabeparameter (alles Referentparameter):
* a, b: Koeffizienten der Regressionsgerade y = ax + b
* r: mittlere quadratische Abweichung
* sa, sb: Standardabweichungen fuer a und b
* Die Funktion liefert im Erfolgsfall 0, wenn die
* Koeffizienten nicht berechnet werden koennen, 1.
* Aufruf: linreg(x,y,anzahl,&a,&b,&r,&sa,&sb);
*/
{
double summexy = 0.0, summex = 0.0;
double summey = 0.0, summex2 = 0.0;
double sum = 0.0;
double divisor = 0.0;
double n = (double) anz;
int i;
for(i = 0; i < anz; i++)
{
summex += x[i];
summey += y[i];
summexy += (x[i] * y[i]);
summex2 += (x[i] * x[i]);
}
divisor = (n*summex2 - summex*summex);
if (divisor < 1.0E-30) return (1); /* Division durch 0! */
/* a und b fuer y = ax + b berechnen */
*a = (n*summexy - summex*summey)/divisor;
*b = (summex2*summey - summex*summexy)/divisor;
/* mittlere quadratische Abweichung */
for(i = 0; i < anz; i++)
sum += pow(*a*x[i] + *b - y[i],2);
*r = sqrt(sum/(n - 2.0));
/* Standardabweichung von a und b */
*sa = *r*sqrt(n/divisor);
*sb = *r*sqrt(summex2/divisor);
return (0);
}
int main(void)
{
double x[] = {1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0};
double y[] = {4.1,6.1,7.9,9.9,12.1,13.8,16.0,18.2,19.9,22.1};
int anz = 10;
double a, b, r, sa, sb;
if(linreg(x,y,anz,&a,&b,&r,&sa,&sb) != 0)
printf("Nicht berechenbar!\n");
else
{
printf("Regressionsgerade: y = %lf * x + %lf\n",a,b);
printf("Mitt. quad. Abweichung: %lf\n",r);
printf("Standardabweichung a: %lf\n",sa);
printf("Standardabweichung b: %lf\n",sb);
}
return 0;
}
|
| |
